

- OpenAI’s latest generative AI model, GPT-4 is by leaps and bounds better at exams than its predecessor, released only a year apart.
- GPT-4 is able to produce distinction-level results in some of the US’ most important and difficult exams during simulations.
- As OpenAI continues to improve its model, it will only get more powerful and nuanced.
This week, the most prominent name in generative artificial intelligence, OpenAI, unveiled the next iteration of its generative pre-trained transformer, GPT-4. A marked improvement over the previous GPT-3.5, GPT-4 can now be fed images as prompts.
In a research blog post, that cites the company’s own whitepaper of the latest model, OpenAI says that while it may not be immediately noticeable how much better GPT-4 is at replicating human communication than its predecessor, the latest version “is more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.”
Where there is a clear distinction between the two models, OpenAI notes, comes in how well GPT-4 does in simulated exams compared to its predecessor. For example, the company says, GPT-4, “passes a simulated bar exam with a score around the top 10 percent of test takers; in contrast, GPT-3.5’s score was around the bottom 10 percent.
In an SAT Math exam, a test usually carried out by universities in the US to make entrance decisions, GPT-4 scores 700/800, or 87.5 percent. That’s a distinction mark in South Africa, by the way. This is compared to 590/800 for GPT-3.5.
In fact, OpenAI saw a marked improvement across all of the simulated tests carried out by GPT-4 over its predecessor.
“We’ve spent 6 months iteratively aligning GPT-4 using lessons from our adversarial testing program as well as ChatGPT, resulting in our best-ever results (though far from perfect) on factuality, steerability, and refusing to go outside of guardrails,” writes OpenAI in the blogpost.
Such a significant improvement is all the more impressive as GPT-3.5 was only trained and launched a year ago.
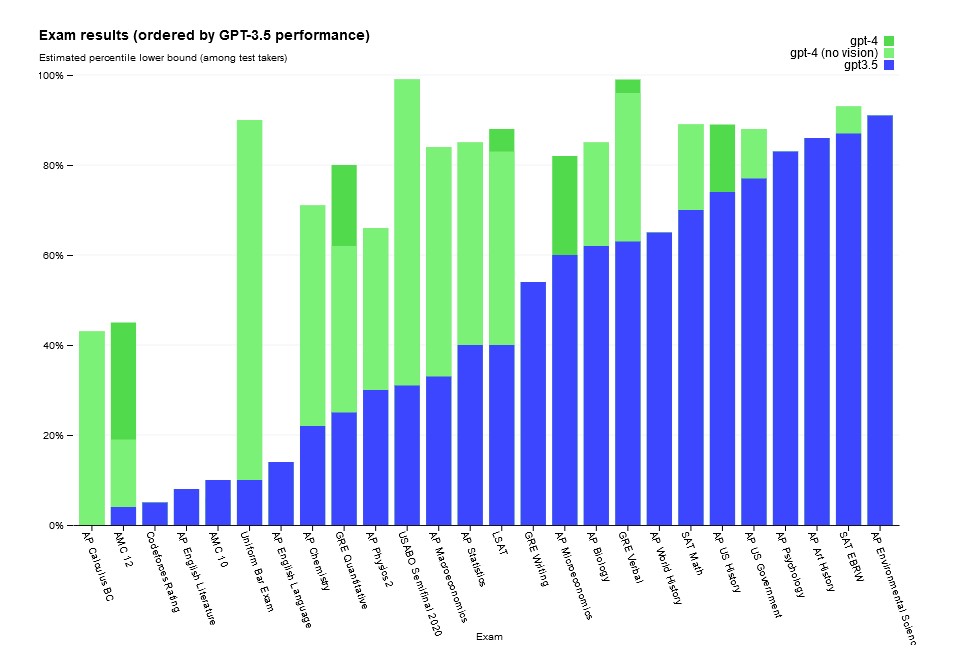
In the whitepaper [PDF], OpenAI notes, “GPT-4 exhibits human-level performance on the majority of these professional and academic exams.”
Concern has risen in education institutions and academic circles on the implications of such powerful and widely accessible language models being used to cheat on exams, write entire essays and bypass learning altogether.
While some teachers and lecturers say that it is very easy to tell when work handed in is made by an AI or if it is authentic, some institutions are still very wary. Earlier this year, the New York education department banned access to ChatGPT across its schools for fear of the site being abused.
As fears rise so do platforms that can counter cheating, like GPTZero, which uses a set of conditions to check whether a text is written by AI or by a human. But with OpenAI expanding and improving its AI by leaps and bounds in short periods of time, especially with the help of Microsoft, it will only get more and more difficult to tell the difference.
OpenAI says that it will release GPT-4’s chat capabilities via ChatGPT, and its soon-to-be-released API. University students interested in finding more honest ways to use ChatGPT to help them with their work can check out this handy guide.
[Image – Pavel Danilyuk on Pexels]

